

How To Get Download Link From Page Source
Learn how to "download" a website with all its resource (scripts, styles and images) with Node.js
Disclaimer
In no case shall we (Our Code Globe) or the programmer of this module be liable for direct, indirect, special or other consequential damages resulting from the use of this module or from the web pages downloaded with this module. Use it at your own chance.
And with our disclaimer we don't talk about that y'all estimator will explode by using the module that we'll utilise to copy a website. We only warn that this script should not exist used for illegal activities (like, imitation a website and expose information technology in another web domain), but learning more than near Node.js and spider web development.
Having said that, have you lot ever seen an crawly website with some awesome gadget or widget that yous absolutely want to accept or learn how to do but you lot don'f find an open up source library that does that? Because as offset step, that's what should do as first, look for an open source library that creates that awesome gadget and if information technology exists, implement information technology in your ain projection. If you don't notice it, then you can use the chrome dev tools to audit the element and see superficially how information technology works and how yous could create information technology by yourself. Withal if you lot're non and then lucky or you don't have the skills to copy a characteristic through the dev tools, then you still take a change to do it.

What would be better than having the unabridged lawmaking that creates the awesome widget and edit it equally yous want (thing that will assist you to empathize how the widget works). That is precisely what you're going to learn in this article, how to download an unabridged website through its URL with Node.js using a web scraper. Web Scraping (too termed Screen Scraping, Spider web Data Extraction, Spider web Harvesting etc) is a technique employed to extract big amounts of data from websites whereby the data is extracted and saved to a local file in your computer or to a database in table (spreadsheet) format.
Requirements
To download all the resource from a website, we are going to apply the website-scraper module. This module allows you to download an entire website (or single webpages) to a local directory (including all the resources css, images, js, fonts etc.).
Install the module in your project executing the following command in the terminal:
npm install website-scraper Notation
Dynamic websites (where content is loaded by js) may be saved not correctly considering website-scraper doesn't execute js, it only parses http responses for html and css files.
Visit the official Github repository for more than information hither.
1. Download a single page
The scrape function returns a Promise that makes requests to all the providen urls and saves all files found with sources to directory. The resources volition exist organized into folders according to the type of resources (css, images or scripts) inside the providen directory path. The following script will download the homepage of the node.js website:
const scrape = require('website-scraper'); allow options = { urls: ['https://nodejs.org/'], directory: './node-homepage', }; scrape(options).and then((upshot) => { console.log("Website succesfully downloaded"); }).catch((err) => { panel.log("An error ocurred", err); }); Salvage the previous script in a js file (script.js) and and then execute it with node using node alphabetize.js. In one case the script finishes, the content of the node-homepage folder volition be:
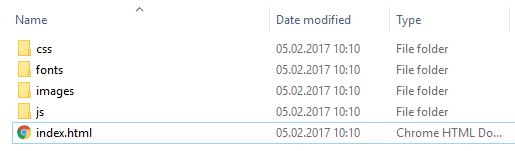
And the index.html file from a web browser will expect like:

All the scripts, style sheets were downloaded and the website works like a charm. Observe that the but fault shown in the console, is due to the analytics script from Google that you lot should obviously remove from the code manually.
two. Download multiple pages
If you're downloading multiple pages of a website, you lot should provide them simultaneously in the same script, scraper is smart enough to know that a resources shouldn't be downloaded twice (just but if the resource has been already downloaded from the same website in some other page) and it volition download all the markup files but non the resources that already exist.
In this case, we are going to download 3 pages of the node.js website (index, about and blog) specified in the urls holding. The content will be saved in the node-website folder (where the script is executed), if it doesn't exists it will be created. To be more organized, nosotros are going to sort out every type of resources manually in different folders respectively (images, javascript, css and fonts). The sources holding specifies with an array of objects to load, specifies selectors and attribute values to select files for loading.
This script is useful if you want specifically some spider web pages:
const scrape = require('website-scraper'); scrape({ urls: [ 'https://nodejs.org/', // Will be saved with default filename 'alphabetize.html' { url: 'http://nodejs.org/about', filename: 'about.html' }, { url: 'http://blog.nodejs.org/', filename: 'blog.html' } ], directory: './node-website', subdirectories: [ { directory: 'img', extensions: ['.jpg', '.png', '.svg'] }, { directory: 'js', extensions: ['.js'] }, { directory: 'css', extensions: ['.css'] }, { directory: 'fonts', extensions: ['.woff','.ttf'] } ], sources: [ { selector: 'img', attr: 'src' }, { selector: 'link[rel="stylesheet"]', attr: 'href' }, { selector: 'script', attr: 'src' } ] }).then(function (event) { // Outputs HTML // console.log(result); console.log("Content succesfully downloaded"); }).catch(role (err) { console.log(err); }); 3. Recursive downloads
Imagine that yous don't need only specific web pages from a website, but all the pages of information technology. A way to exercise it, is to utilise the previous script and specify manually every URL of the website that you can get to download information technology, however this can be counterproductive because information technology will take a lot of time and you volition probably overlook some URLs. That's why Scraper offers the recursive download characteristic that allows you to follow all the links from a page and the links from that folio and and then on. Obviously, that would atomic number 82 to a very very long (and virtually infinite) loop that you lot tin limit with the max allowed depth (maxDepth property):
const scrape = require('website-scraper'); let options = { urls: ['https://nodejs.org/'], directory: './node-homepage', // Enable recursive download recursive: true, // Follow only the links from the first folio (alphabetize) // so the links from other pages won't be followed maxDepth: 1 }; scrape(options).then((result) => { console.log("Webpages succesfully downloaded"); }).catch((err) => { panel.log("An error ocurred", err); }); The previous script should download more pages:
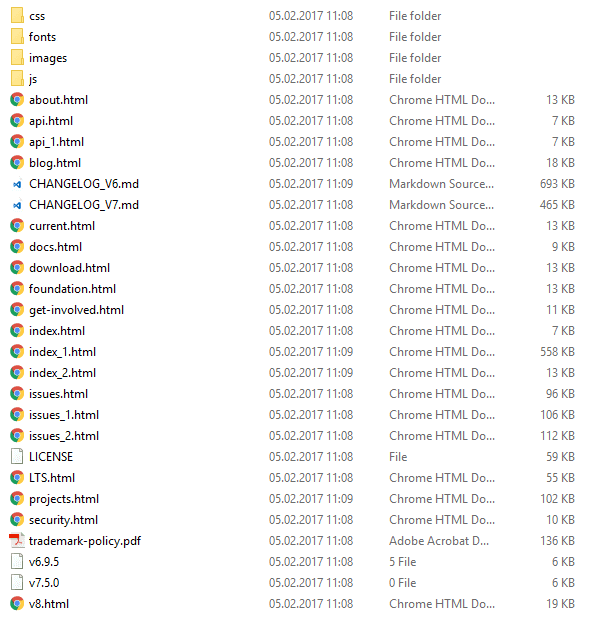
Filter external URLs
Equally expected in any kind of website, there will be external URLs that don't belong to the website that you want to re-create. To foreclose that those pages are downloaded also, you can filter it only if the URL matches with the one you apply:
const scrape = require('website-scraper'); const websiteUrl = 'https://nodejs.org'; permit options = { urls: [websiteUrl], directory: './node-homepage', // Enable recursive download recursive: true, // Follow only the links from the beginning page (index) // and then the links from other pages won't exist followed maxDepth: 1, urlFilter: part(url){ // If url contains the domain of the website, then keep: // https://nodejs.org with https://nodejs.org/en/example.html if(url.indexOf(websiteUrl) === 0){ console.log(`URL ${url} matches ${websiteUrl}`); return truthful; } render fake; }, }; scrape(options).then((result) => { console.log("Webpages succesfully downloaded"); }).catch((err) => { console.log("An error ocurred", err); }); That should subtract in our instance the number of downloaded pages:
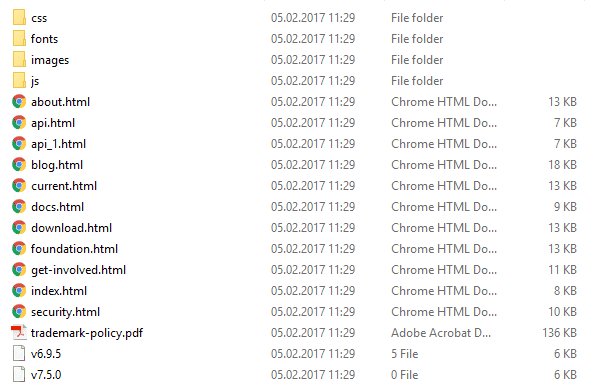
4. Download an unabridged website
Note
This task require much time, so exist patient.
If you want to download an entire website, y'all tin employ the recursive download module and increase the max allowed depth to a reasonable number (in this example not so reasonable with 50, but whatever):
// Downloads all the crawlable files of example.com. // The files are saved in the same structure equally the structure of the website, by using the `bySiteStructure` filenameGenerator. // Links to other websites are filtered out by the urlFilter const scrape = crave('website-scraper'); const websiteUrl = 'https://nodejs.org/'; scrape({ urls: [websiteUrl], urlFilter: part (url) { return url.indexOf(websiteUrl) === 0; }, recursive: truthful, maxDepth: 50, prettifyUrls: true, filenameGenerator: 'bySiteStructure', directory: './node-website' }).so((data) => { console.log("Entire website succesfully downloaded"); }).take hold of((err) => { console.log("An error ocurred", err); }); Final recommendations
If the CSS or JS lawmaking of the website are minified (and probably all of them will exist), we recommend yous to use a beautifier mode for the language (cssbeautify for css or js-beautify for Javascript) in order to pretty print and brand the code more readable (not in the same way that the original code does, but acceptable).
Happy coding !

How To Get Download Link From Page Source,
Source: https://ourcodeworld.com/articles/read/374/how-to-download-the-source-code-js-css-and-images-of-a-website-through-its-url-web-scraping-with-node-js
Posted by: davidsonstan1962.blogspot.com
0 Response to "How To Get Download Link From Page Source"
Post a Comment